
在 Proxmox VE 上面運作的虛擬機器越來越多情況下,若又是搭配 Share Storage,遇到效能問題時要怎麼追查到底是那一台 VM 造成的呢?
雖然 PVE 已經有為每一台虛擬機器提供 Summary 概觀,點進去 Dashboard 儀表板可以查到 Disk I/O 效能圖表,但是問題來了。
這個功能一次只能查看一台虛擬機器,要比對不同台的時候要不斷的切來切去,既浪費時間也無法一次比對,效益太差,更致命的問題是,沒辦法切換要看的時間範圍,過去的時間無法查看,也無法調整刻度。

PVE 虛擬機器磁碟 IO 效能圖表
有沒有什麼比較好的方法可以方便的查看呢?
方案一:LibreNMS
有看到我過去文章的朋友一定知道,我是 LibreNMS 的超級愛好者,經由 LibreNMS 可以做到非常多的監控能力,簡單好用。

LibreNMS
可惜,人生偶爾會遇到幾個 But。

LibreNMS 查看磁碟 I/O 效能
LibreNMS 非常好用,但偏偏在做磁碟 I/O 效能監測就是他的罩門,遇到幾個問題:
- 無法一次查看所有虛擬機磁碟 I/O 效能數據 (無法以 PVE Host 取出)
- Windows 作業系統無法提供磁碟 I/O 效能數據 (無法以 PVE Guest 取出)
- 無法容易的將所有虛擬機排在同一張圖表上比對效能
- 無法做到小於分鐘級的時間粒度效能監測 (無法看到即時與精確的數據)
尤其是最後一點,是重要的問題所在,因此這個情況需要考慮其它方案。
方案二:netdata
netdata 是一款數據即時又詳細的監控工具,在絕大多數需要小於分鐘級的監測,我會使用 netdata。

netdata
可惜,人生偶爾又遇到很多個 But。

netdata 查看磁碟 I/O 效能
netdata 精美、快速、好用,但偏偏在做 PVE 虛擬機器的磁碟 I/O 效能監測也是他的罩門,遇到幾個問題:
- 無法查看虛擬機磁碟 I/O 效能數據 (無法以 PVE Host 取出)
- Windows 作業系統不支援 (無法以 PVE Guest 取出)
- 無法容易的將所有虛擬機排在同一張圖表上比對效能
- 無法跨機器做效能圖表總覽
尤其是第一點,雖然可以參考前陣子的另一篇文章使用,但該文章是針對虛擬磁碟放在本機 ZFS 裡面的才有用,這次的案例是放在 Share Storage 上,並沒有辦法一體適用。因此,還是需要考慮其它方案。
方案三:Prometheus + Grafana
Prometheus 與 Grafana 是兩套非常熱門的開源套件,當它們強強聯手以後,是極具彈性、數據即時又詳細的監控工具組合,在絕大多數需要小於分鐘級且需要交叉比對的監測,我才會使用它們。
在此提供快速的中文發音法:Prometheus = 普羅米修斯,Grafana = 廣發納。

Prometheus

Grafana
前面我用了「才使用」這個詞,為什麼會不常用它呢?
因為 Grafana 的圖表需要手工定製,不像 LibreNMS 或 netdata 那樣,安裝好就已有許多現成圖表或套件可以使用,前置作業較為耗時。
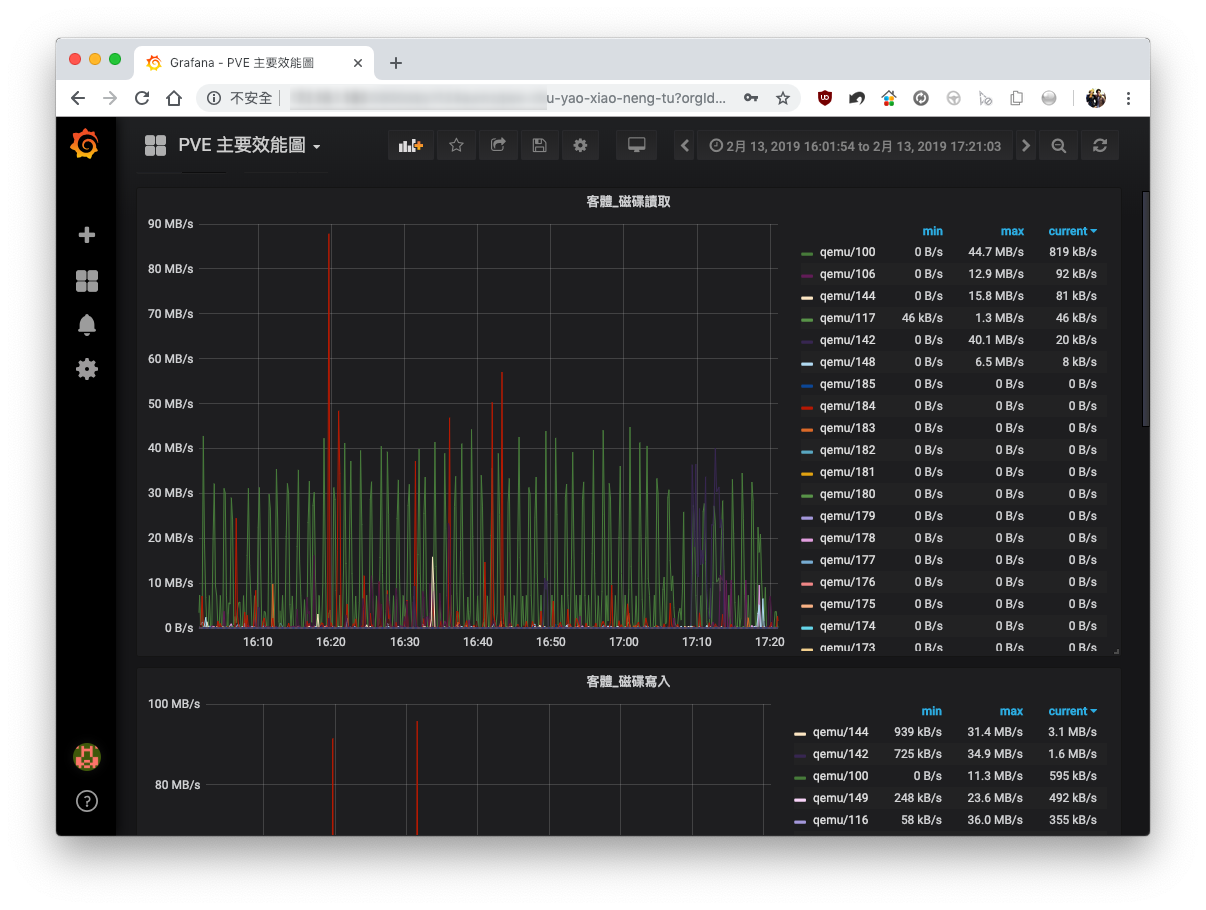
Prometheus + Grafana 查看 PVE 磁碟 I/O 效能
經過一連串的建置與調整程序後,成功的在 Grafana 上呈現 PVE 的所有客體機 (KVM 虛擬機器 + LXC 容器) 磁碟 I/O 圖。
在這張圖中,讓我一眼就看出異常的頻繁讀取的虛擬機器,從而對症下藥進行處理。
為什麼說是從這張圖才能看到?難道 PVE 儀表板提供的圖不可以嗎?讓我們來看看:

Grafana 數據圖表

PVE 效能數據圖表
這種差距的問題來自於先前提到的時間粒度問題,不夠精細導致遺失許多重要的細節。
舉個例子,過去我在 LibreNMS 推廣簡報上用一張圖解釋了時間粒度的重要性:

不同監測工具的時間粒度差異圖
由上而下分別是 LibreNMS、Proxmox VE、netdata,可以在這張比對圖中非常清楚的看到細節失真程度。
雖然說越精細越能看出問題,但別忘記了,精細的數據是要用系統效能、儲存空間換來的。因此,要針對需要的項目再做,以免還沒做好效能監測,這台監測主機自己就先把自己給拖垮了。
如何使用
要讓 PVE 的數據接到 Grafana 顯示,並不是那麼容易的事,我們需要以下的多種套件。
- Prometheus
- Grafana
- Prometheus Proxmox VE Exporter
由於 Prometheus 與 Grafana 都是較為複雜的套件,無法在這一一介紹,在此假設已經預先安裝好這兩個套件,並且已俱備相關基礎知識。
可以使用 pip 指令直接安裝,若沒有 pip,請先參考相關教學完成後再回頭來做。
安裝 Prometheus PVE Exporter
pip install prometheus-pve-exporter
接著,請先在 PVE WebUI 上建立一個 Role 角色,使其具有 PVEAuditor 的權限,接著再建立一個帳號並賦予他剛剛建立的 Role 角色。

建立好效能監控用的角色

將效能監控用的角色指派給帳號
接下來,請建立 pve.yml,內容如下:
建立 pve.yml 設定檔
default:
user: monitoring@pve
password: yourpassword
verify_ssl: false
完成後,即可執行 pve_exporter 讓他運作起來,如果 pve.yml 在其它位置,也可以在後面用帶入完整的路徑與檔名資訊。
再來,請到 Prometheus 上進行設定,讓 Prometheus 開始對 pve_exporter 進行資料 Pull 拉取。
修改 prometheus.yml 設定檔
- job_name: 'pve'
static_configs:
- targets:
- 192.168.100.172 # Proxmox VE node.
metrics_path: /pve
params:
module: [default]
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.100.172:9221 # PVE exporter.
到這裡即可完成 Prometheus 的相關設定。
下一步,請登入 Grafana 在儀表板上選擇建立 Graph 圖表,在 Data Source 處選擇 Prometheus,並到 Query 欄位處輸入 pve_ 開頭的字串,即可將需要的數據做為圖表呈現。

Grafana 設定 pve_exporter 提供數據

Grafana 顯示 pve_exporter 效能數據
pve_exporter 所能提供的數據有以下幾種:
- pve_cluster_info
- pve_cpu_usage_limit
- pve_cpu_usage_ratio
- pve_disk_read_bytes
- pve_disk_size_bytes
- pve_disk_usage_bytes
- pve_disk_write_bytes
- pve_guest_info
- pve_memory_size_bytes
- pve_memory_usage_bytes
- pve_network_receive_bytes
- pve_network_transmit_bytes
- pve_node_info
- pve_storage_info
- pve_up
- pve_uptime_seconds
- pve_version_info
由於名稱已經足夠淺顯易懂,就不做解釋,但使用到 pve_disk_read_bytes / pve_disk_write_bytes 之類的數據時要注意,他所提供的數字是「總量」。
若想要知道每一個時間點當時的存取量是多少,請在 Grafana 上搭配 Prometheus PromQL 的 irate 或 rate 函數,才能取得正確結果,函數的使用感謝 邱宏瑋 Hwchiu 大大指點。
結論
效能監測與問題找尋,需要先了解什麼樣的問題場景,以及數據與時間的對應關係,才能從中選擇正確的工具以及資料來源,對症下藥,精確打擊。
參考資料
- [議程簡報]LibreNMS 企業實戰經驗分享
https://blog.jason.tools/2018/11/librenms-slideshare.html
- [經驗分享]找尋虛擬機磁碟 I/O 效能問題所在
https://blog.jason.tools/2019/01/disk-perf-issue.html - netdata/netdata: Real-time performance monitoring, done right!
https://github.com/netdata/netdata
- Grafana - The open platform for analytics and monitoring
https://grafana.com/
- Prometheus - Monitoring system & time series database
https://prometheus.io/
- znerol/prometheus-pve-exporter: Exposes information gathered from Proxmox VE cluster for use by the Prometheus monitoring system
https://github.com/znerol/prometheus-pve-exporter